
前 OpenAI CTO Mira Murati 拿下 1GW 算力大单:AI 竞赛开始拼电厂
本文最后更新于 2026-04-12,文章内容可能已经过时。
想象一下,你每天刷到的 AI 新模型越来越聪明,但背后真正的战场,已经从实验室的代码行,转移到了占地数公顷、耗电堪比一座城市的“AI工厂”。2026 年3 月10 日,前 OpenAI CTO Mira Murati创办的 Thinking Machines Lab 与 NVIDIA宣布多年轻量级战略合作——至少1GW(吉瓦)规模的下一代 Vera Rubin 系统。这不是一条普通的融资新闻,而是 OpenAI核心人才出走后,第一次用“基础设施级”动作向全世界宣告:下一代前沿模型的胜负手,已经从参数规模升级为算力、系统与生态的硬核比拼。
这条消息对中国 AI 用户来说,尤其值得关注。它提醒我们,全球 AI军备竞赛已进入“电厂时代”,而我们普通开发者和企业,最该做的不是追逐天价 GPU,而是学会用最灵活、最低成本的方式,第一时间用上最新模型。
Mira Murati 的“第二次创业”:从 OpenAI离场到1GW落地2024 年9 月25 日,Mira Murati 在 X 上宣布离开 OpenAI。这位2018 年加入 OpenAI、曾短暂担任临时 CEO、主导 ChatGPT、DALL·E、Sora 等产品的技术掌门人,给出的理由是“想给自己留出探索空间”。半年后,2025 年2 月,她在旧金山创办 Thinking Machines Lab,一家定位为“公共利益公司”的 AI研究与产品实验室。
公司成立仅5个月,就完成了史上最大规模的种子轮——20亿美元融资,估值120亿美元,领投方 a16z,投资者阵容里赫然包括 NVIDIA、AMD、Cisco 和 Jane Street。团队核心几乎是 OpenAI “老兵”:首席科学家 John Schulman(ChatGPT核心发明人之一)、CTO Barret Zoph,以及来自 Meta、Mistral 的顶尖研究员。他们的公开目标很清晰:构建“可定制、可理解、与人类协作”的通用智能系统,强调开放科学与实际落地,而不是单纯追求参数最大化。
2026 年3 月10 日的 NVIDIA合作,是这家新公司第一次真正“亮剑”。合作内容包括:
-部署至少1GW 的 NVIDIA Vera Rubin下一代系统(2027 年初启动);
- NVIDIA进行“重大战略投资”;
Mira Murati 在公告中说:“NVIDIA 的技术是整个领域的基础,这份合作将加速我们构建人们能真正塑造、属于自己的 AI。” Jensen Huang则称这是“推动 AI基础设施向新高度迈进的关键一步”。
这笔合作,把“前 OpenAI核心成员创业”从人事八卦,升级成了产业级信号。
###1GW算力到底有多“史诗级”?小白也能懂的对比很多人看到“1GW”只会觉得“很大”,但真正理解它的量级,才能明白为什么这是拐点。
1GW =1000MW,相当于一座中型核电站的满负荷发电能力,足以给旧金山全城供电(约80-100 万户家庭)。放到 AI 数据中心语境下,它意味着:
- 单集群规模:足以支撑数十万张下一代 GPU同时运行(以当前 Blackwell/ Vera Rubin架构估算,一个机架功率可达80kW,是传统服务器的5-10倍)。
- 能耗对比:xAI Colossus 一期约300MW,已是全球最大单体 AI集群;OpenAI Stargate 项目目标1.2GW;Meta Hyperion规划更高。1GW意味着 Thinking Machines Lab 一上来就站在了“全球头部梯队”的门槛上。
- 真实瓶颈:如今训练前沿模型,买 GPU早已不是难题,真正卡脖子的是电力供应、散热系统、网络互联和智能调度。1GW级项目需要专门的变电站、液冷设施、甚至自建发电厂,这才是 NVIDIA作为“卖铲人”最核心的价值——它不只卖芯片,还在帮客户构建完整的“AI工厂”。
用一张直观的信息图来看(如下),AI 数据中心的功耗已远超传统计算:单个 AI GPU处理器功率700-1200W,对比传统 CPU仅150-200W;到2028 年,单个训练站点可能就需要1GW电力。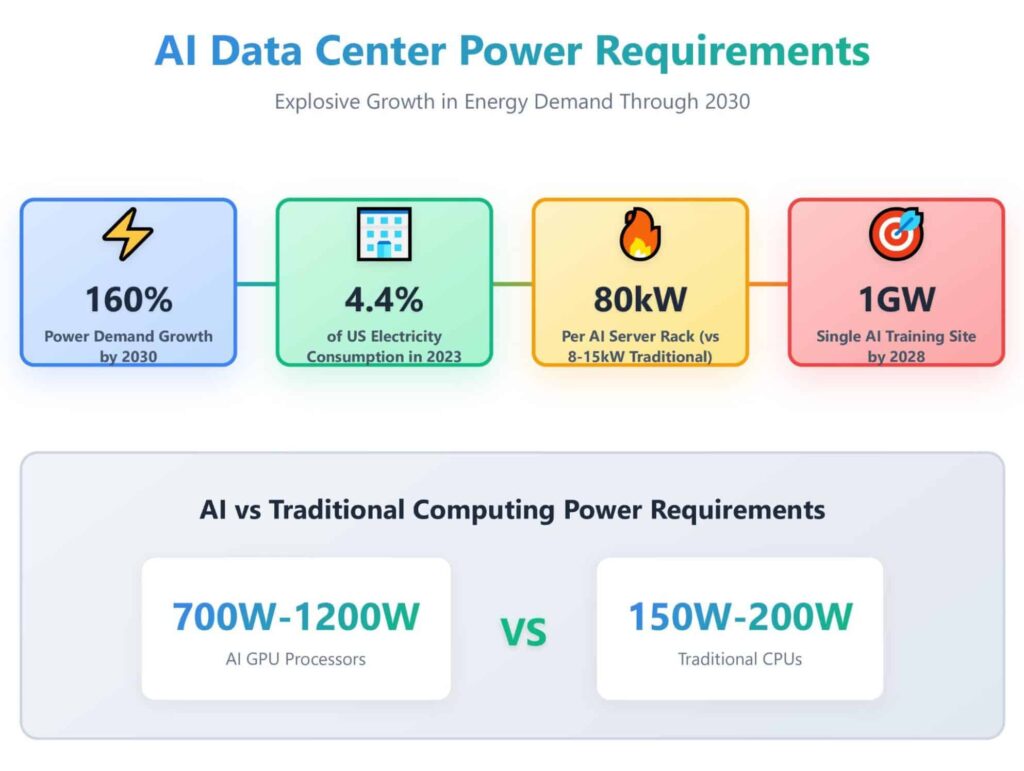
金句:参数是“武器”,算力才是“后勤”。没有稳定1GW级电力供应,再强的架构也只是纸上谈兵。
Thinking Machines Lab到底想造什么?瞄准“下一代前沿模型”
Murati团队的背景决定了这家公司不会做普通垂类应用。他们押注的方向,很可能是:
- 更强的多模态与代理式 AI:让模型不仅“会聊天”,还能真正“做事”——自主规划、工具调用、长期记忆。
- 强调对齐与可定制:Murati反复强调“人们能塑造的 AI”,暗示更开放的权重、更好的人类反馈机制,以及企业级定制能力。
- 基础模型新架构:可能结合 OpenAI时期的经验,探索推理能力指数级提升的新路径,而不是简单堆参数。
一家新公司一上来就锁定1GW级算力,信号非常明确:它要进的是“基础模型头部牌桌”,而非做应用层 SaaS。这也解释了为什么资本和 NVIDIA愿意重仓——他们赌的是 Murati团队能复制甚至超越 OpenAI早期的爆发力。
这对全球与中国 AI产业意味着什么?
全球格局:前 OpenAI人才出走正形成一股新势力。xAI 有 Elon Musk 的 Colossus,Anthropic绑定 AWS/Google,Meta 自建超大规模 GPU集群。现在 Thinking Machines Lab 用1GW直接“入场”,证明 NVIDIA依然是最大赢家——无论谁赢,它都卖铲子。 对中国的影响(这才是我们最关心的):- 模型能力迭代更快:前沿模型训练成本虽高,但分摊到 API后的单次调用价格可能继续下降,同时推理能力、上下文长度、多模态体验会显著提升。
- 开源 vs闭源竞争加剧:国内 Deepseek、通义千问、Kimi 等免费/低价模型,会面临更强的全球闭源对手,倒逼本土厂商在性价比和生态上加速创新。
- 企业采购逻辑变化:不能只看“参数大”,更要看稳定性、调用成本、上下文窗口和生态适配。算力绑定越来越紧,国内云厂商与芯片/数据中心的深度合作(如华为云、阿里云、腾讯云的专属集群)将成为标配。
- 普通开发者红利:你不需要自己建1GW工厂,就能通过统一平台调用全球最新模型,成本可控。
对比表一目了然(部分公开数据估算):
|公司 |核心人物背景 | 当前/规划算力 |融资/估值 |主要方向 | | Thinking Machines Lab | Mira Murati + OpenAI老兵 |1GW+ (2027) |20亿种子,120亿估值 | 可定制协作智能 | | xAI | Elon Musk | Colossus1GW+ | 重金自建 |最大规模训练集群 | | OpenAI | Sam Altman | Stargate1.2GW |微软深度绑定 |通用前沿模型 | | Anthropic | Dario Amodei | 多云合作数百 MW |亚马逊/Google |安全对齐模型 | | Meta | Mark Zuckerberg | Hyperion 多 GW | 自建 | 开源 Llama生态 |###普通开发者和企业,现在该怎么选、怎么做?
答案很简单:别押注单一玩家,先把“多模型灵活调用”能力搭起来。
在前沿模型格局快速变化的今天,最聪明的策略是:
1. 用统一接口测试不同模型在写作、代码、分析、多模态等场景的表现;
2. 根据任务类型、成本、速度动态切换(例如推理重任务用旗舰模型,日常用快速免费模型);
3.避免被单一平台锁死,保持技术中立。
对大多数人来说,真正重要的不是自己造1GW算力,而是第一时间、低成本地用上最新模型。
8848AI平台就是为此而生:注册即用(用户名+密码,无需邮箱验证),新注册用户自动送50 万 token,想要更多可通过工单联系客服申请,再手动赠送200 万 token。国产模型(Deepseek R1、Qwen3、Kimi K2.5、GLM-5)完全免费,无月租、按量付费,平台内置对话功能,网址 api.884819.xyz。想亲自感受前沿模型差异?从一个最简单的 API 请求开始:
``bashcurl https://api.884819.xyz/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY" \
-d '{
"model": "Deepseek R1",
"messages": [
{"role": "user", "content": "用通俗中文解释1GW算力到底意味着什么,以及它对普通开发者有什么影响"}
]
}'
``复制粘贴就能跑,5分钟内你就能对比不同模型的实际表现。
行动建议:现在就去 api.884819.xyz注册,拿免费 token跑几个测试任务。把多模型调用能力变成你的“第二大脑”,无论模型格局怎么变,你都能始终站在能力曲线的最前端。1GW算力只是门票,真正稀缺的,可能不是模型,而是支撑这些模型的“电”。如果说这次合作宣告了基础设施时代的到来,那么下一篇,我们就来深挖:AI时代真正卡脖子的资源,到底是芯片,还是电力?以及中国企业该如何提前布局。
本文由8848AI原创,转载请注明出处。关注8848AI,带你从零开始学AI。#AI新闻 #算力大战 #MiraMurati #NVIDIA #ThinkingMachinesLab #人工智能 #8848AI #AI基础设施 #前沿模型 #AI产业观察









