

Gemini Embedding 2 发布:多模态 RAG 终于要像人一样检索了
想象一下:你公司有几百份 PDF规章制度、几千张产品设计图、几十小时的培训录音,还有一堆演示视频。以前想让员工一句“这个模块的 UI改动记录在哪?”就能同时搜出文档、截图和会议录音,几乎得搭三四个不同的管道——文本转 embedding、图片 OCR再 embedding、音频 ASR转文字再 embedding。工程量大、效果打折、维护头疼。
现在,Google DeepMind 在2026 年3 月10 日正式发布了 Gemini Embedding2。它把这一切直接扔进同一个向量空间,原生处理文字、图片、视频、音频和 PDF,不再需要中间转码。这不是又一个“参数小升级”,而是把多模态检索从“拼积木”变成了“一张图”。
对普通用户,它意味着未来的 AI搜索会更懂你“看得见、听得懂”的真实世界;对开发者,它意味着跨模态 RAG、统一知识库的落地门槛大幅降低。读完这篇,你可能会立刻打开电脑,想跑一个 Demo试试——因为这事,真的要改变了。
##这次更新为什么值得关注?
过去做向量检索,最痛苦的地方在于“模态割裂”。文本用 text-embedding-ada-002,图片得用 CLIP,音频先 ASR转文字再 embed,视频更麻烦。每一类模态都有自己的向量空间,跨模态检索要么效果差,要么得维护多套索引。
Gemini Embedding2直接说:我们把所有模态放进同一套“语义坐标系”。一句话概括它的核心意义——首次实现原生多模态嵌入,让“文本找图片、视频找文档、音频找答案”变得自然而然。
这对小白用户意味着什么?以后问 AI“上个月产品发布会里,设计师提到的新配色方案在哪里”,它能直接把会议录音片段、PPT截图和文字记录一起拉出来,不再是“文本优先”的笨办法。
对开发者来说,更直接:多模态 RAG 的工程复杂度有望下降50%以上。以前你要分别处理数据清洗、转码、索引对齐,现在一个 API就能搞定统一索引。Google官方明确表示,这模型专为跨模态语义搜索、文档检索和推荐系统设计,支持100+语言,中文表现自然在列。
它不是“又一个新模型”,而是把多模态检索从概念推向可工程化的拐点。接下来,真正值得关注的,是它会如何重塑我们每天都在用的知识库和搜索产品。
Gemini Embedding2到底是什么?“原生多模态向量模型”意味着什么?
先说 embedding是什么。简单类比:embedding就像给每一段内容在高维空间里找一个“坐标”。坐标越接近,语义越相似。机器通过比较向量距离,就能快速找到“最像”的内容。
传统 embedding 大多是“单模态”或“伪多模态”:
- 单模态:只吃文本,或只吃图片。
Gemini Embedding2 是原生多模态。模型本身就理解多种输入,直接把它们映射到同一个3072维向量空间。官方定义是:“我们的首个原生多模态嵌入模型,将文本、图片、视频、音频和文档(PDF)映射到单一嵌入空间,支持跨媒体的多模态检索和分类。”
关键差异在这里:没有信息损耗。一段视频的动态画面、音频的语调起伏、PDF 的排版布局,都能被模型原生编码,而不是被“转文字”简化掉。
官方支持规格(截至发稿,gemini-embedding-2-preview公开预览版):
- 向量维度:3072维- 输入模态:文本(最高8192 tokens)、图片(单次最多6 张)、视频(最高120秒)、音频(最高80秒,原生处理无需 ASR)、PDF(支持多页文档)
- 可用平台:Gemini API 和 Vertex AI- 语言支持:100+种,覆盖中文等主要语言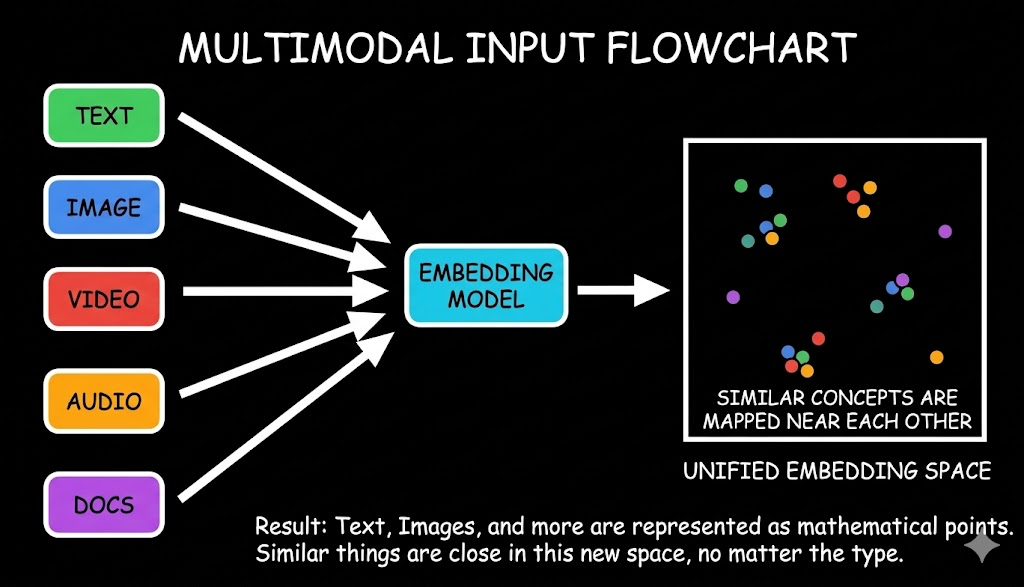
这张图直观展示了整个流程:左边五种模态输入 → 中间 Gemini Embedding2 →右边统一向量空间,所有相似内容自然聚拢。
##它会改变哪些实际应用场景?
真正让 Gemini Embedding2落地的,是“统一入口”带来的场景重构。以下是三个中国用户最容易代入的案例。
1.企业知识库 / RAG 系统一家中型制造企业,内部有产品规格 PDF、设计师的 UI截图、工厂培训录音、装配演示视频。以前做知识库,要分开建四个索引,用户问“新款手机的防水测试标准”时,经常只能搜到文字,错过视频里的实操演示。现在用 Gemini Embedding2,一个向量库就能全部装下。一句查询,就能同时召回 PDF 第3页、对应产品图、培训视频的45秒片段。工程团队反馈:检索准确率提升明显,维护成本直接砍半。 2.内容搜索与推荐短视频平台或知识付费 App,用户输入“如何用 AI做短视频剪辑的 BGM选择逻辑”。传统方案可能只推文字教程,现在能直接推荐相关短视频片段、播客音频、教程 PDF里的配图。推荐不再是“文本匹配”,而是真正的“多模态语义匹配”,用户粘性自然上来。 3.电商、教育、客服场景-电商:用户拍一张竞品照片,就能搜到自家同款的详情页文案、客服录音、宣传视频。-教育:学生问“这个知识点老师在第3节课怎么讲的”,系统同时给出讲义 PDF、板书截图、课堂录音片段。
-客服:用户语音投诉,系统秒匹配历史工单截图、处理视频教程。
这些场景的共同点是:同一向量空间让“统一检索”从理想变成现实。Google官方也强调,它特别适合“所有模态都在描述同一件事”的高重叠场景。
对开发者意味着什么?机会、门槛与现实挑战机会:-跨模态检索、统一索引、混合知识库的搭建门槛大幅降低。
- RAG应用从“文本优先”转向“多模态优先”,产品体验直接起飞。
- 存储与计算:3072维向量比传统1536维占用更多空间,大型知识库要考虑向量数据库选型(如 pgvector、Milvus)。
- 数据清洗:视频/音频仍需合理切片,PDF排版复杂时效果可能受影响。
- 召回偏差:多模态混合索引偶尔会出现“视觉主导”或“音频主导”的偏差,需要精心设计检索策略和 rerank层。
- 中文适配:100+语言支持下中文效果不错,但行业专有名词、方言口语仍建议做少量领域微调或后处理。
真正的难点,从来不在调 API,而在数据组织、检索策略和评估体系。调通 embedding只是第一步,后面的 RAG管道优化才是长期功课。
##普通用户现在应该怎么看?开发者又该怎么上手?
普通用户可以这么看:这代表 AI工具正在真正“多感官化”。以后你不用再把问题拆成纯文字,拍张照片、发段语音、扔个 PDF就能得到精准答案——AI越来越像一个懂你所有表达方式的助手。
开发者上手建议:
1.去 Google AI Studio 或 Vertex AI申请预览访问(model名为 gemini-embedding-2-preview)。
2. 先跑个最小 Demo:把不同模态内容 embed后,用 FAISS 或 Chroma建个小索引,测试跨模态检索。
3.评估自己的业务场景:如果知识库里多模态内容占比高,值得立刻验证。
如果你不想分别折腾 Google API、OpenAI、各种开源模型的接入流程,想快速对比效果、跑通 embedding + RAG工作流,推荐直接用聚合平台。像 [api.884819.xyz](https://api.884819.xyz)这样的平台,支持多模型统一调用,注册即送体验额度,国产模型完全免费,按量付费没有月租。对想低成本验证多模态方案的团队来说,能把“从看到新闻到跑出 Demo”的周期缩短到半天。
最小可运行代码示例(Python + Gemini API):``pythonimport google.generativeai as genaigenai.configure(api_key="YOUR_API_KEY")
model = genai.GenerativeModel('gemini-embedding-2-preview')
result = model.embed_content(
contents=[
"产品防水测试标准", #文本 genai.types.Part.from_bytes(data=image_bytes, mime_type="image/png"), #图片 genai.types.Part.from_bytes(data=video_bytes, mime_type="video/mp4"), #视频 genai.types.Part.from_bytes(data=audio_bytes, mime_type="audio/mpeg"), #音频 genai.types.Part.from_bytes(data=pdf_bytes, mime_type="application/pdf"), # PDF ]
)
print(result.embeddings) # 返回3072维向量列表``
把向量存进向量数据库,就能实现跨模态检索了。完整 Demo流程不复杂,关键是先把数据喂进去。
传统 vs 原生多模态 embedding对比表 |对比维度 |传统单模态 embedding | OCR/ASR后转文本 embedding | Gemini Embedding2 原生多模态 | | 支持模态 |单一(文本或图片) |伪多模态 | 原生多模态(5种统一) | |信息损耗 | 无(但只限单模态) | 高(转文字丢失视觉/听觉信息) |极低 | |工程复杂度 |低 | 高(多管道+对齐) | 中(统一 API) | |跨模态检索体验|几乎无 |一般 |优秀 | |适用场景 |简单文本搜索 |早期多模态尝试 |企业知识库、推荐、智能搜索 |##写在最后Gemini Embedding2 最值得关注的,不是它又多支持了几种输入,而是它把“多模态统一检索”从概念进一步推向可工程化。AI应用正在从“文本优先”转向“多模态优先”,下一代搜索和知识产品,会越来越接近我们人类本来的认知方式。
普通用户,继续关注这些更新就好——你的 AI助手会越来越“懂”你。开发者,别只看新闻,尽快跑个 Demo验证自己的业务场景,才是真正的机会。
如果你更关心实际效果,下一篇我们直接实操:手把手教你用 Gemini Embedding2搭一个“能同时搜 PDF、图片、语音、视频”的多模态知识库 Demo,看看在中文企业场景里它到底能打几分。想先跑通流程的读者,可以现在就去 [api.884819.xyz](https://api.884819.xyz)注册体验——新注册用户系统自动送50 万 token,更多额度也可通过工单申请。
期待你的 Demo成果,咱们下一期见。
本文由8848AI原创,转载请注明出处。关注8848AI,带你从零开始学AI。#Gemini Embedding2 #多模态向量 #RAG #向量检索 #Google DeepMind #AI知识库 #多模态搜索 #8848AI #AI开发者 #企业AI应用










